.svg)
Definition: Was ist ein LLM überhaupt?
Ein Large Language Model (LLM) ist ein künstliches Intelligenz-System, das trainiert wurde, menschliche Sprache zu verstehen und zu generieren. Die drei Wörter bedeuten:
- Large (Gross): Milliarden bis hunderte Milliarden von Parametern (mathematische Gewichte)
- Language (Sprache): Spezialisiert auf Text- und Sprachverarbeitung
- Model (Modell): Ein mathematisches System, das Muster erkennt und vorhersagt
Einfach gesagt: Ein LLM ist eine "Wahrscheinlichkeitsmaschine" – es berechnet, welches Wort oder welcher Satz als Nächstes folgen sollte, basierend auf Milliarden von Trainingsdaten und komplexer Mathematik.
Beispiele im Alltag:
- ChatGPT (OpenAI)
- Claude (Anthropic)
- Gemini (Google)
- LLaMA (Meta)
- Mistral (europäisch)
Wie funktioniert ein LLM? Der technische Kern
Während unser Gehirn durch Erfahrung, Gefühle und Erinnerungen lernt, lernt ein LLM durch riesige Mengen an Textmaterial:
- Webseiten und Wikipedia
- Bücher und akademische Artikel
- Forenbeiträge und Kundenfeedback
- Programmiercode
- Millionen von Gesprächen
Das Modell "liest" diese Texte nicht zur Wissensspeicherung, sondern zur Mustererkennung. Es merkt sich nicht, was konkret in einem Text stand, sondern wie Sprache aufgebaut ist.
Die vier Kernschritte eines LLM:
1. Tokenisierung – Sprache in Zahlen umwandeln
LLMs können nicht direkt mit Text arbeiten. Sie brauchen Zahlen. Im ersten Schritt wird jedes Wort oder jeder Wortteil in Tokens zerlegt – in numerische Codes, die das Modell verarbeiten kann.
Beispiel:
Satz: "Die Sonne geht auf"
Tokens: [123, 456, 789, 101]
2. Embeddings – Bedeutungen erkennen
Jedes Token wird in einen multidimensionalen Raum abgebildet. "Sonne" und "Mond" sitzen näher beieinander als "Sonne" und "Schuhe", weil ihre Bedeutung ähnlich ist. Diese Embeddings ermöglichen es dem Modell, Wörter zu verstehen.
3. Transformer & Attention – Der intelligente Teil
Der Transformer ist die revolutionäre Architektur (2017 erfunden) hinter modernen LLMs. Sein Geheimnis sind Attention Mechanisms – diese zeigen dem Modell, welche Wörter wichtig sind.
Wenn du schreibst: "John spielte den Ball. Er war schnell." – Das Modell erkennt durch Attention-Mechanismen, dass "Er" sich auf "John" bezieht, nicht auf "Ball".
4. Generierung – Vorhersage des nächsten Wortes
Der LLM wählt das statistisch wahrscheinlichste nächste Wort. Dies geschieht Wort für Wort, Satz für Satz:
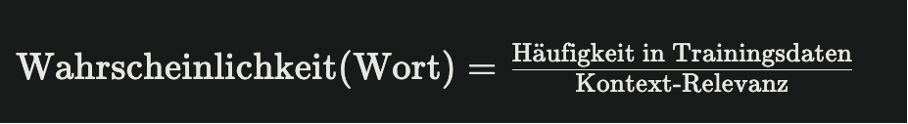
Das Ergebnis ist deine AI-Antwort.
Der kritische Unterschied: Verstehen vs. Berechnen
Das ist die wichtigste Erkenntnis:
Ein LLM versteht nicht – es berechnet. Das ist ein fundamentaler Unterschied.
Mensch vs. LLM – Ein Beispiel:
Aufgabe: Ergänze: "Die Sonne geht im ___ auf."
Ein Mensch denkt:
- "Ich weiss aus Geografie: Die Sonne geht im Osten auf."
- "Ich verbinde dies mit meinem Schulwissen, meiner Erfahrung."
Ein LLM rechnet:
- "In Milliarden Trainingsdaten folgt nach 'Sonne geht im' am häufigsten das Wort 'Osten'."
- "Also wähle ich 'Osten'."
Das Ergebnis ist gleich – der Weg ist fundamental anders.
Das ist auch, warum LLMs manchmal "halluzinieren" – erfundene Fakten mit Selbstbewusstsein präsentieren. Sie wissen nicht, was wahr ist. Sie wissen nur, was statistisch passt.
Grösse zählt: Warum "Large" entscheidend ist
LLMs bestehen aus Parametern – Millionen oder Milliarden von numerischen Gewichten, die das Modell während des Trainings optimiert.
| Modellgrösse | Parameter | Fähigkeiten | Herausforderungen |
| Klein | 1–10 Milliarden | Einfache Textklassifikation, mobil | Niedrige Qualität, begrenzte Nuancen |
| Mittel | 20–70 Milliarden | Gute Textgenerierung, Code | Moderate Kosten, gute Balance |
| Gross | 100–500+ Milliarden | Komplexes Reasoning, Kreativität | Hohe Kosten, lange Antwortzeit |
Grössere Parameter = Komplexere Muster, bessere Ergebnisse – aber höhere Kosten und längere Verarbeitung.
Was LLMs können und was nicht: Eine ehrliche Bilanz
LLMs sind exzellent bei:
- Textgenerierung: Artikel, E-Mails, Marketingkopien
- Zusammenfassung: Lange Dokumente verkürzen
- Code-Generierung: Programmieren unterstützen
- Brainstorming: Ideenfindung und Konzepte
- Übersetzung: Zwischen Sprachen
- Kommunikation: Kundensupport, FAQ-Bots
LLMs sind unzuverlässig bei:
- Faktenchecking: Halluzinieren Fakten frei erfundenes Wissen
- Mathematik & Logik: Rechenfehler
- Aktuelle Events: Wissen endet bei Trainingsdatum
- Vertrauliche Daten: Ausgabe könnte trainiert werden
- Kritische Entscheidungen: Brauchen immer menschliche Prüfung
- Rechtliche Expertise: Keine juristische Verantwortung
Das Halluzinations-Problem: Eine kritische Warnung für Unternehmen
LLM-Halluzinationen sind möglicherweise die grösste Herausforderung für den Enterprise-Einsatz.
Definition: Das Modell erzeugt Ausgaben, die faktisch korrekt klingen, aber völlig erfunden sind.
Praxis-Beispiel:
Ein Finanzteam nutzt ein LLM zur Erstellung von Quartalsergebnissen. Das Modell "halluziniert" mehrere Finanzkennzahlen. Die falschen Zahlen werden versehentlich in den offiziellen Bericht aufgenommen. Rechtskonsequenzen folgen.
Arten von Halluzinationen:
| Art | Beschreibung | Beispiel |
| Faktische Halluzination | Erfundene, falsche Fakten | "Wikipedia wurde 1995 gegründet" (falsch: 2001) |
| Semantische Halluzination | Logisch widersprüchlicher Text | "Das Produkt ist kostenlos und kostet CHF 99.-" |
| Attribution Halluzination | Falsche Quellenangaben | "Zitat von Einstein" (nie gesagt) |
Wie Unternehmen damit umgehen:
- RAG verwenden (Retrieval Augmented Generation): Das LLM greift auf externe, verifizierte Datenquellen zu.
- Fact-Checking-Systeme implementieren
- Menschliche Kontrolle: Expertenprüfung vor Veröffentlichung
- Versionskontrolle: Audit-Trails für alle KI-Ausgaben
Mehr zu diesem Thema in unserem Guide zu RAG-Systemen und Company GPT →
Die verschiedenen Typen von LLMs: Eine Übersicht
| Typ | Beispiele | Besonderheiten | Best For |
| Proprietary (Geschlossen) |
GPT-4, Claude, Gemini | Beste Leistung, Cloud-basiert, Lizenzgebühren | Enterprise, hohe Anforderungen |
| Open Source (Offen) |
LLaMA, Mistral, Falcon | Lokal hosting-bar, volle Kontrolle, DSGVO-konform | DACH-Unternehmen, Datenschutz-kritisch |
| Spezialisiert | LawGPT, MedGPT | Domänenwissen, optimiert für ein Feld | Jura, Medizin, Finanzen |
| On-Premise/ Self-Hosted |
Beliebige Modelle, eigengehostet | Maximale Sicherheit, 100% Datenkontrolle | Behörden, kritische Infrastruktur |
DSGVO-Tipp: Für Unternehmen in der Schweiz und der EU ist der Datenspeicherungsort kritisch. Viele proprietäre US-Modelle versenden Daten über den Atlantik – problematisch für sensitive Daten. Open-Source-Modelle auf europäischen Servern sind sicherer.
Praktische Use-Cases: Wo LLMs im Business Wert schaffen
- Customer Support & FAQ Bots
LLMs beantworten häufige Kundenanfragen automatisch, senken Response-Zeiten um 70%.
- Content Generierung & Marketing
Blog-Artikel-Skizzen, Produktbeschreibungen, Social Media Copy – LLMs sind Ideenlieferanten.
- Dokumentenverarbeitung & RAG
Dank RAG-Systemen (wie Company GPT von NORTHBOT) können LLMs unternehmensgeheime Dokumente analysieren und intelligente Antworten geben – ohne Datenlecks.
- Code-Generierung
LLMs wie Claude oder GPT-4 generieren qualitativ hochwertigen Code – eine enorme Produktivitätssteigerung für IT-Teams.
- Mitarbeiter-Onboarding
Ein LLM-basierter HR-Bot beantwortet interne Fragen zu Richtlinien, Urlaub, IT-Setup automatisch.
LLMs vs. klassischer KI: Wo liegt der Unterschied?
| Aspekt | Klassische KI / ML | LLM / Generative AI |
| Eingabe | Strukturierte Daten, Zahlen | Text, Sprache, Kontext |
| Ausgabe | Klassifikation, Vorhersage | Generative Inhalte, Konversation |
| Training | Supervised Learning, Klassifizierung | Self-Supervised Learning, Unsupervised |
| Grösse | Millionen Parameter | Milliarden Parameter |
| Kosten | Mittel | Hoch (beim Inference) |
| Beispiele | Spam-Filter, Betrugserkennung, Prognosen | ChatGPT, Claude, Copilot |
2025 Trend: LLMO (Large Language Model Optimization)
So wie Unternehmen für Google SEO optimieren, müssen sie jetzt auch für Large Language Model Optimization (LLMO) optimieren. Das bedeutet:
Ihre Inhalte müssen nicht nur für Suchmaschinen, sondern auch für ChatGPT, Claude und Perplexity sichtbar sein.
LLMO-Best-Practices:
- Klare Struktur: H1, H2, H3 – LLMs brauchen Hierarchie
- Prägnante Zusammenfassungen: LLMs priorisieren Klarheit über Umschreibung
- Zitierfähige Quellen: Mit Links und Publikumsdatum
- Semantische Tiefe: Nicht nur Keywords, sondern echte Bedeutung
- Factuality & EEAT: Expertise, Autorität, Vertrauenswürdigkeit
Fazit: LLMs sind Werkzeuge, keine Magier
Large Language Models sind mächtige Werkzeuge – aber sie sind nicht intelligent im menschlichen Sinne. Sie sind:
- ✅ Hervorragend bei Mustererkennung
- ✅ Schnell bei Textgenerierung
- ✅ Nützlich für Automation
- ❌ Nicht bewusst
- ❌ Nicht zuverlässig bei Fakten
- ❌ Nicht selbstständig denkend
Die Zukunft liegt nicht in "Mensch vs. Maschine", sondern in "Mensch + Maschine".
Für Unternehmen bedeutet das:
- Wähle das richtige LLM für deinen Use-Case
- Implementiere Kontrollen gegen Halluzinationen
- Trainiere deine Teams zum sicheren Umgang
- Miss den ROI – nicht alle LLM-Einsätze sind wirtschaftlich
Dein nächster Schritt: LLMs richtig implementieren
Möchtest du verstehen, wie dein Unternehmen von LLMs profitieren kann? NORTHBOT berät dich bei der Auswahl, Integration und Optimierung von KI-Lösungen – mit Fokus auf Sicherheit, Compliance und Business-Impact.
Unsere Lösungen für Unternehmen:
- Company GPT: Dein unternehmenseigenes LLM, trainiert auf eurem Wissen
- KI Dokumentenmanagement: RAG-basierte intelligente Suche
- KI Meeting Assistant: LLM-basierte Protokollierung & Zusammenfassungen
